Design Considerations
Table of contents
Data
Entities in the data repository are checked by the CI. On commit, the CI tests all entities and prepares a report of failing and succeding entities. This report is commited to the ackrep_ci_results repo. Additionally binary data such as plots and notebook htmls are prepared as artifacts. Once the CI is done, a webhook is triggered, prompting the server to download the artifacts and pulling the latest CI results.
Core
Error Propagations
The debugging of errors in the data repository is difficult, since the respective scripts are called via subprocess. The resulting challenge is to create a pipeline for both usefull debug messages and outputs in the nominal case. The following graphic depicts how error messages that arise during the execution of the execscript are propagated:
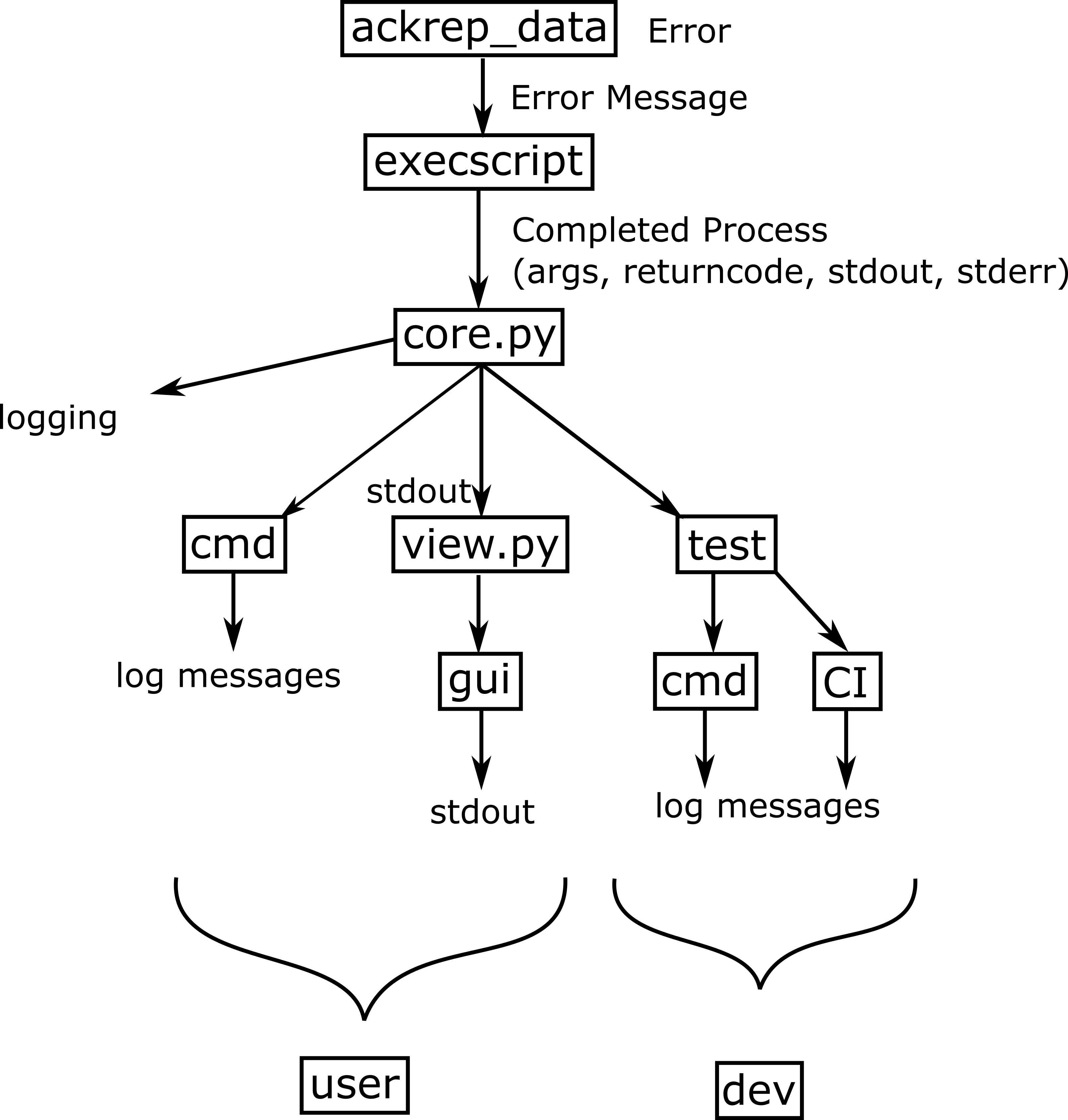
Which information is show in the different cases of settings, error type and execution methode is shown the following table:
Web Gui |
cmd |
||
|---|---|---|---|
settings.DEBUG == True |
settings.DEBUG == False |
||
nominal |
show output, result: “success” |
show output, result: “success” |
log, “success” |
numnerical error |
show output, result: “inaccurate” |
show output, result: “inaccurate” |
log, “inaccurate” |
script error |
show debug, result: “script error” |
result: “script error” |
log, “fail” |
Web
Unittests
problems:
loading db inside container
inside container there is no difference between ut and normal use case
solution:
ut-repo gets a permanently broken system model for testing debug messaging (LRHZX)
to distinguish between ut and nominal use case, environment variables are passed with the docker command to the container, specificly tailored to work inside the container
CI
Docker can be run by adding the step:
- setup_remote_docker:
version: 20.10.14
docker_layer_caching: true
volume mounting does not exist inside CI (see https://circleci.com/docs/2.0/building-docker-images/#mounting-folders). The used workaround is to create a dummy container with a dummy volume (without mapping to host!), copy all files into the dummy container (at the volume location) and the start the main container with
--volumes-from dummy.The image url part of the tests is skipped when in the CI since the file would have to be copied back to the primary container during the test.
Webhook
circle ci api v1
https://circleci.com/docs/api/v1/index.html#artifacts-of-the-latest-build
Note
api v1 gonna be depricated soon
api v2 not very explicit, didnt work
https://circleci.com/docs/api/v2/index.html#operation/getJobArtifacts
Debugging
Frequent Problems:
permission denied for container when accessing data files. This might not be visible on first glance, so when a web test of TestCases2 fails, add
core.logger.critical(response.content.decode("utf8"))after the sleep command. This should give a more detailed error message.
Deployment
Concept
TODO All entities in the data repo are checked via CI. The results of the tests as well as potential binary data (e.g. plots) are stored as artifacts. The results in the form of a yaml file are committed to the ackrep_ci_results repo by the CI. After every test tun, a webhook is triggert, so prompt the server to download the most recent results and binary data. This is shown when one visits the view entity detail view.
With the env container not being reloaded for every check, it is important to make sure that the correct database is loaded. E.g. in local testing, one might run ackrep -cwd UXMFA which refers to the ackrep_data repo, after which one might run a unittest for ackrep web, which expects ackrep_data_for_unittests to be loaded. Therefore, the enviroment variables of the data repo (ACKREP_DATA_PATH) inside and outside docker are compared. If there is a difference, the running container is shut down to make sure the correct db is loaded on the following startup.
data repo
Sharing Volumes:
The ackrep_data repository is not part of the docker images. Rather it is mounted to each container on their respective startup. Naturally, after mounting the volume the database has to be loaded in each container, which is done by an entrypoint script.
The volume mapping is specified in the docker-compose.yml file, which in turn is called by the start_docker.py script. Mountaing a volume to containers is easily done for the ackrep-django and celery_worker container but is problematic for the environment containers. Although these are started from inside the celery_worker container (reminder that this creates siblings, and not docker in docker) the volume mapping still has to be host/.../ackrep_data:code/ackrep_data. This means the celery_worker container has to have some information abour its context. This is done by passing the DATA_REPO_HOST_ADDRESS env variable from the starter script first to the celery_worker container and then to the env container with the correct volume mapping. In case of local running without ackrep-django container, this env variable is created by the celery process which runs directly on host and thus knows the data repo location. In the unit test case, instead of ackrep_data, ackrep_data_for_unittests is mounted and the corresponding environment variables are passed.
Loading the Database:
Since the data is only ever added on container startup, the databases are loaded by the entrypoint script of each container. In the case of the environment containers, the correct environment variable has to be passed for the database loading to happen. An exemplary docker command issued by the celery process (core.py/check) could look like this:
normal case:
docker-compose --file ../ackrep_deployment/docker-compose.yml run --rm
-e ACKREP_DATABASE_PATH=/code/ackrep_core/db_for_unittests.sqlite3
-e ACKREP_DATA_PATH=/code/ackrep_data_for_unittests
-v /home/Documents/ackrep/ackrep_data:/code/ackrep_data
default_environment
ackrep -c UXMFA
unittest case:
docker run --rm
-e ACKREP_DATABASE_PATH=/code/ackrep_core/db_for_unittests.sqlite3
-e ACKREP_DATA_PATH=/code/ackrep_data_for_unittests
--volumes-from dummy
ghcr.io/ackrep-org/default_environment
ackrep -c LRHZX
Since the introduciton of a shared data volume (containing ackrep_data + _for_unittests) mounted simultaniously to all containers, the environment container faces the problem of when to load the database, since its normally only spun up for a single ackrep command and stopped and removed afterwards. In order to increase performance, the environment containers are recycled as follows:
Structogram of core.py/check(key):
get_entity
get env key
try to find running env container id
if container exists
if container has INcorrect db loaded
shutdown container
if container NOT already running:
if image available locally:
docker-compose run –detached env_name bash
else: # pull image from remote
docker run –detached ghcr.io/../env_name bash
wait for container to load its database
get container id
docker exec id ackrep -c key
The environment container runs detached (in the background). After it loaded its database (via entrypoint script) it runs a dummy command (bash) in order to remain started. Now it can be accessed via docker exec commands without the need to reload the database.
Note
Running the remote image with docker run: Even though we are running the container in the background (detached -d), we still have to specify -ti (terminal, interactive) to keep the container running in idle (waiting for bash input). Otherwise, the container would stop after running the entrypoint script (load db). This is noteworthy, since -d and -ti seem to be contradictory. (see commit)
Note
The latest environment images are only ever pulled from github on container startup, meaning when a container is put into idle, not when it is accessed via docker exec. This means, that to make sure that the most recent version of an environment is used, the currently running environment container has to be shutdown manually from time to time.
On the Topic of File Ownership:
Sharing a volume between a host and a container is cause for the host filesystem owner matching problem. This blog post goes into details about it and how to combat it. In short, host and container both need to have read+write access to the data in the volume. This is achieved by creating a dummy user inside the container and initally running the container as root. On startup (when running the entrypoint script), we change the user id of the dummy user inside the contianer to match the hosts user id. Afterwards, we switch the user insde the container from root to dummy, so all existing files as well as all newly created files can be accessed (and edited) by both dummy and host user.
This of course is only half the truth since containers are started in two different ways as described above. Most of the time, the a running container is accessed via docker exec and therefore does not run the entrypoint script. In order to still simulate the same user inside the container as on the outside, we use the --user <host_uid> option.
Docker Naming Conventions
Our docker images are created locally, with the docker-compose build command. Since the docker-compose.yml is located in the ackrep_deployment directory, this directory is prepended to the specified service name. This results in the following image names:
ackrep_deployment_ackrep-django
ackrep_deployment_celery_worker
ackrep_deployment_default_environment
Some images are pulled from remote, resulting in image names such as:
redis:6.2-alpine
ghcr.io/ackrep-org/default_environment
Using the above mentioned images, containers can be spun up. Using docker-compose the containers have the same name as the compose service.
The environment containers are started differently, using the run argument with an ackrep command. Therefore, the container is called
ackrep_deployment_default_environment_run_<hash>
When adding new environments, the following files have to be named in s specific manner:
<name>of the environment:<some_description>_environmentmetadata.yml: name:
<name>Dockerfile:
Dockerfile_<name>(docker compose service:
<name>, for dev only)
Image Publishing
The push_image.py script helps with publishing new verions of environments.
Syntax: python push_image.py -i <image_name> -v <x.y.z> -m "<message>"
Additionally, the most recent commits of ackrep_core and ackrep_deployment are added to the message. Best practice to avoid confusing behavior in the CI would be:
locally commit change to core
rebuild images, test behavior
if approved, commit and push changes to ackrep_deployment (dockerfiles)
run push_script to update remote images
push core commits to trigger CI
The script create a label in the dockerfile and rebuild the image with the label. Afterwards it uploads the image with the specified version and updates latest tag.